
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.test</groupId> <artifactId>Kafka-Demo</artifactId> <version>0.0.1-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.10</artifactId> <version>0.9.0.0</version> </dependency> <dependency> <groupId>io.appium</groupId> <artifactId>java-client</artifactId> <version>6.0.0-BETA5</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.4</version> </dependency> </dependencies> </project>
2、生产者
package com;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class KafkaProducer {
private final Producer<String, String> producer;
public final static String TOPIC = "linlin";
private KafkaProducer() {
Properties props = new Properties();
// 此处配置的是kafka的端口
props.put("metadata.broker.list", "127.0.0.1:9092");
props.put("zk.connect", "127.0.0.1:2181");
// 配置value的序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
// 配置key的序列化类
props.put("key.serializer.class", "kafka.serializer.StringEncoder");
props.put("request.required.acks", "-1");
producer = new Producer<String, String>(new ProducerConfig(props));
}
void produce() {
int messageNo = 1000;
final int COUNT = 10000;
while (messageNo < COUNT) {
String key = String.valueOf(messageNo);
String data = "hello kafka message " + key;
producer.send(new KeyedMessage<String, String>(TOPIC, key, data));
System.out.println(data);
messageNo++;
}
}
public static void main(String[] args) {
new KafkaProducer().produce();
}
}
右键:run as java application,执行前需要启动Zookeeper、kafka,具体操作详见
http://zhangwenlongchina.iteye.com/admin/blogs/2420493
运行结果:
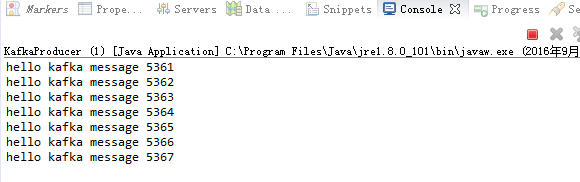
3、消费者
package com;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.serializer.StringDecoder;
import kafka.utils.VerifiableProperties;
public class KafkaConsumer {
private final ConsumerConnector consumer;
private KafkaConsumer() {
Properties props = new Properties();
// zookeeper 配置
props.put("zookeeper.connect", "127.0.0.1:2181");
// group 代表一个消费组
props.put("group.id", "lingroup");
// zk连接超时
props.put("zookeeper.session.timeout.ms", "4000");
props.put("zookeeper.sync.time.ms", "200");
props.put("rebalance.max.retries", "5");
props.put("rebalance.backoff.ms", "1200");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "smallest");
// 序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
ConsumerConfig config = new ConsumerConfig(props);
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(config);
}
void consume() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(KafkaProducer.TOPIC, new Integer(1));
StringDecoder keyDecoder = new StringDecoder(new VerifiableProperties());
StringDecoder valueDecoder = new StringDecoder(new VerifiableProperties());
Map<String, List<KafkaStream<String, String>>> consumerMap = consumer.createMessageStreams(topicCountMap, keyDecoder, valueDecoder);
KafkaStream<String, String> stream = consumerMap.get(KafkaProducer.TOPIC).get(0);
ConsumerIterator<String, String> it = stream.iterator();
while (it.hasNext())
System.out.println("<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<" + it.next().message() + "<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<");
}
public static void main(String[] args) {
new KafkaConsumer().consume();
}
}
运行结果:
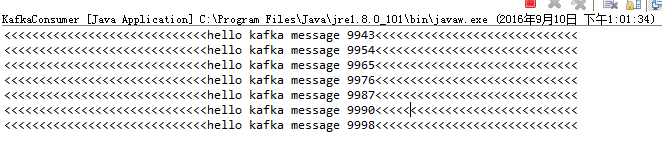



相关推荐
研究了一段时间的kafka。做了一个kafka安装到java接口的使用。适合kafka入门
kafka集成springboot,简单的一个收发实例,kafka入门 kafka集成springboot,简单的一个收发实例,kafka入门
简单介绍了kafka的入门操作,快速搭建一个实例,以及讲解了kafka消费者组的概念
简单介绍了kafka的入门操作,快速搭建一个实例,以及讲解了kafka消费者组的概念
1.kafka的初认识 2.Kafka 基础实战 :消费者和生产者实例 3.Kafka 核心源码剖析 4.Kafka 用户日志上报实时统计
一本经典的kafka入门书籍。 Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行...
《Kafka入门与实践》中的大量实例来源于作者在实际工作中的实践,具有现实指导意义。相信读者阅读完本书之后,能够全面掌握Kafka的基本实现原理及其基本操作,能够根据书中的案例举一反三,解决实际工作和学习中的...
kafka生产者和消费者实例,了解Kafka的一个简单入门实例源码下载
kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper...
本示例基于框架TypeScript入门资料库构建。 它与kafkajs集成在一起,并简化了对kafka主题的订阅和发布消息。 在找到更多信息 安装 $ yarn install 运行应用 步骤1 确保已安装docker&docker-compose。 # Run ...
入门克隆此仓库git clone https://github.com/oslabs-beta/JMXScripter.git 在根文件夹node index.js运行该应用程序重要笔记默认情况下,从您的Kafka实例从JMX导出器导出的信息被写入localhost:7075。 如果要更改此...
在此处设置您的免费 Apache Kafka 实例: : 配置 export CLOUDKARAFKA_BROKERS="host1:9094,host2:9094,host3:9094"可以在 CloudKarafka 实例的详细信息视图中找到主机名。 export CLOUDKARAFKA_USERNAME=...
如果您急于入门,请Kafka-Pixy并继续使用所选武器的快速入门指南: , 或 。 如果您想使用其他语言,则仍然可以使用其中的任何指南作为灵感,但是您需要自己从生成gRPC客户端存根(有关详细信息,请参阅)。 主要...
当工作流实例达到特定活动时,将消息发送到Kafka主题。 请注意,一条message更确切地说是一个卡夫卡record ,通常也称为event 。 这是Kafka Connect演讲中的消息来源。 消耗来自Kafka主题的消息,并将它们与工作...
Datastax企业版4.8 Apache Kafka 0.8.2.2,我使用了Scala 2.10构建吉特sbt ## Kafka入门请使用以下步骤在此示例中设置Kafka的本地实例。 此基于apache-kafka_2.10-0.8.2.2。 ### 1。 找到并下载Apache Kafka 可以在...
第12天-高级-etcd、contex、kafka消费实例、logagent 第13天-实战-日志管理平台开发 第14天-实战-商品秒杀架构设计与开发 第15天-实战-商品秒杀开发与接入层实现 第16天-实战-商品秒杀逻辑层实现 第17天-实战-商品...
使用KSQLDB将数据从Splunk流到Kafka进行过滤,同时保留所有Splunk元数据(源,源类型,主机,事件) v1.00,2020... 入门提升Docker撰写能力[来源,重击] docker-compose up -d确保一切正常并运行[来源,重击] #docker
启动您的Kafka实例。 使用Docker的示例: docker run -p 9092:9092 -e ADV_HOST=127.0.0.1 lensesio/fast-data-dev 定义您的KQ worker.py模块: import logging from kafka import KafkaConsumer from kq import ...
此脚本生成的 AMI 应该是用于实例化 Kafka 服务器(独立或集群)的那个。 入门 脚本工作需要一些东西。 先决条件 Packer 和 AWS 命令行界面工具需要安装在您的本地计算机上。 要构建基本映像,您必须知道要构建...